はじめに
PFN岡之原さんのTwitterでも話題になっていたRepVGG.手を動かしながら見ていきたいと思います.
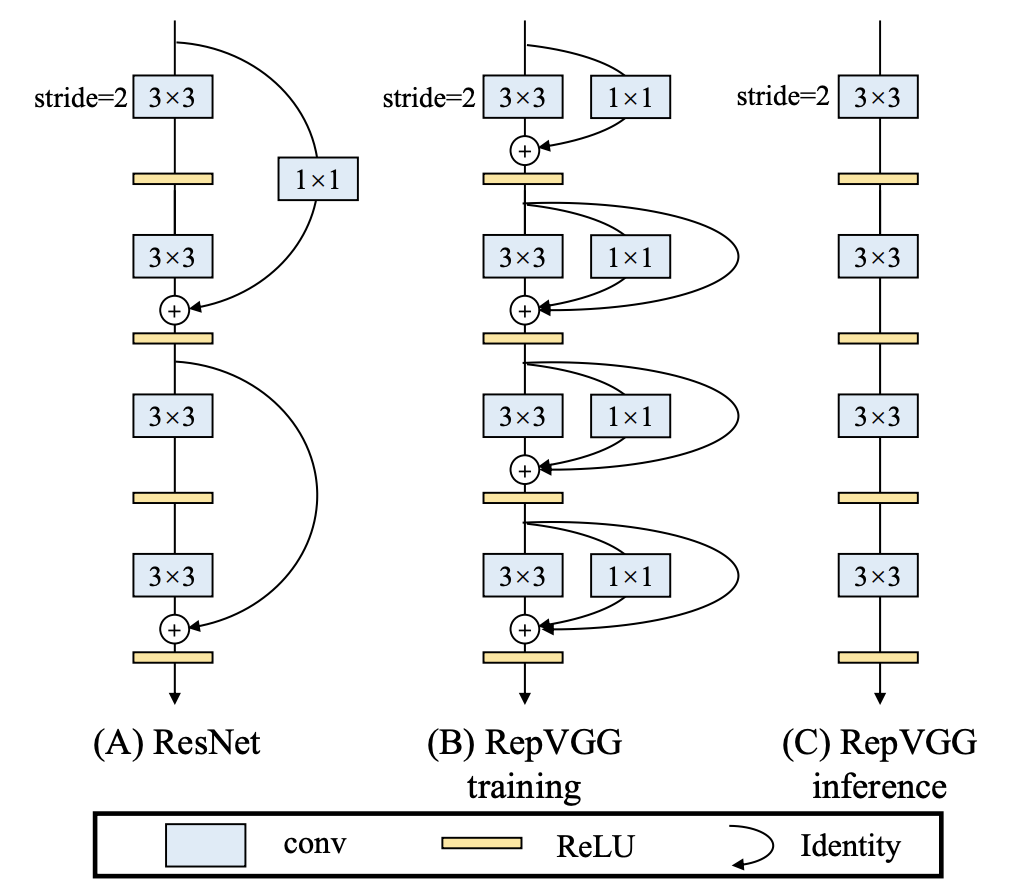
学習は上図(B)のとおり,3x3conv,1x1conv,skip-connectionにそれぞれbatch normalizationが続く3つのブランチで行われますが,学習後に,これを一つの3x3convに変換します.従って推論時には上図(C)のとおり,分岐やskip-connectionを用いないシンプルなネットワークになります.著者らによると,学習済モデルと推論用モデルの出力の差は1e-10程度に収まるそうです.
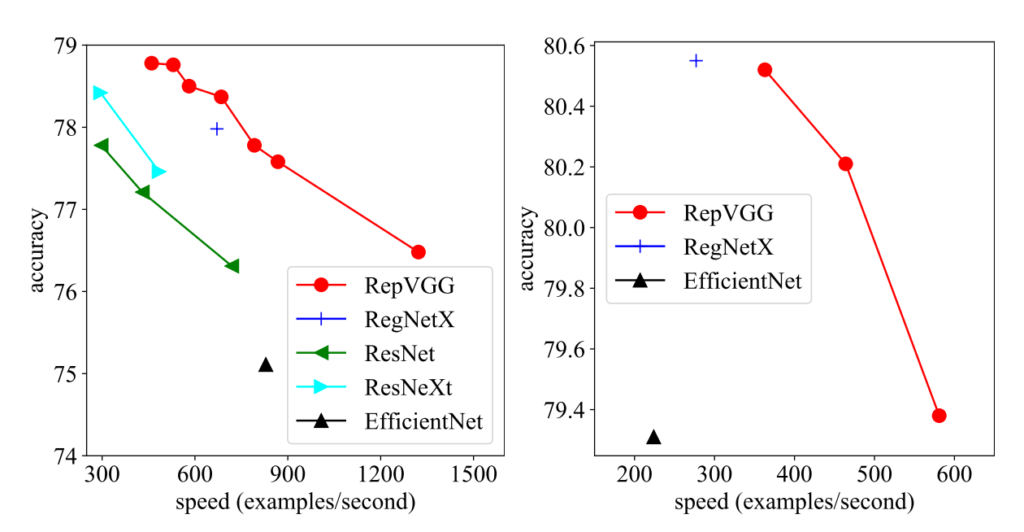
処理スピードが1秒あたり約1,300枚で,識別性能が76%以上.2021年現在,ImageNet Top-1 accuracyのSOTAは90%を超えつつありますが,シンプルなネットワークでEfficientNetを超えるスピードと精度を達成している点が凄さかと思います.GPU等ではもちろん,大量の3x3convとReLUユニットから成るRepVGGに特化した推論用ハードウェアで相当な性能が出るだろう,と著者らは主張しています.
論文とソースコードは以下です.# タイトルもイカしてます.
では,動かし方を早速見ていきましょう.
実行手順
GitHubを見ると,INSTALL.md や requirements.txt 等が見当たりませんが,ぱっと見たところ,PyTorch, Torchvisionとnumpyがあれば動きそうです.ということでPythonは v3.8.5を使い,以下のパッケージを導入してみます.
- numpy==1.20.1
- torch==1.7.1
- torchvision==0.8.2
次に学習済モデルを入手するのですが,ダウンロードサイトを見るとTable.4に記載のモデルがずらっと並んでいます.今回は上記の「1秒あたり約1,300枚で,識別性能が76%以上」のlightweightなモデルを試したいと思いますので,RepVGG-A2-train.pthを入手すると良さそうです.
また,動かすにはImageNetのtrain/valデータが必要ですので,予め用意しておきます.さらに,validationは下記のようなサブフォルダ構成になっている必要がある(ILSVRC2012_img_val.tarをそのままvalディレクトリに展開するのではダメ)という点に注意します.
train/
├── n01440764
│ ├── n01440764_10026.JPEG
│ ├── n01440764_10027.JPEG
│ ├── ......
├── ......
val/
├── n01440764
│ ├── ILSVRC2012_val_00000293.JPEG
│ ├── ILSVRC2012_val_00002138.JPEG
│ ├── ......
├── ......
このため,ここの手順に沿って,例えば次のようにします.
$ mkdir -p ~/data/ILSVRC2012
$ cd ~/data/ILSVRC2012
### extract train data
$ mkdir train
$ cd train
$ tar xvf ~/Downloads/ILSVRC2012_img_train.tar
$ find . -name "*.tar" | while read NAME ; do mkdir -p "${NAME%.tar}"; tar -xvf "${NAME}" -C "${NAME%.tar}"; rm -f "${NAME}"; done
### extract val data
$ cd ..
$ mkdir val
$ cd val
$ tar xvf ~/Downloads/ILSVRC2012_img_val.tar
$ wget
https://raw.githubusercontent.com/jkjung-avt/jkjung-avt.github.io/master/assets/2017-12-01-ilsvrc2012-in-digits/valprep.sh
$ bash ./valprep.sh
これで準備が揃いました.実行します.”train”の後ろに,先ほどダウンロードした学習済モデルを指定します.
python test.py ~/data/ILSVRC2012 train RepVGG-A2-train.pth -a RepVGG-A2
この結果
RepVGG Block, identity = None ... => loading checkpoint 'RepVGG-A2-train.pth' Test: [ 0/500] Time 2.582 ( 2.582) Loss 4.1327e-01 (4.1327e-01) Acc@1 92.00 ( 92.00) Acc@5 98.00 ( 98.00) Test: [ 10/500] Time 0.075 ( 0.610) Loss 7.1487e-01 (4.3962e-01) Acc@1 85.00 ( 89.55) Acc@5 96.00 ( 97.00) ... * Acc@1 76.488 Acc@5 93.022
と出ました.精度はほぼ論文通りですね.実行時間はTesla V100 GPUで約5分でした.
ただ,上記の性能は,最初の図で言うところの(B)のモデルによるものでした.いよいよこの学習済モデルを,本研究のオリジナリティである3x3ConvとReLUのみから成る「推論用モデル」に変換します.どれくらい精度が維持されるか楽しみです.
python convert.py RepVGG-A2-train.pth RepVGG-A2-deploy.pth -a RepVGG-A2
推論用モデルを使うときは,実行コマンドが少し変わります.
python test.py ~/data/ILSVRC2012 deploy RepVGG-A2-deploy.pth -a RepVGG-A2
さて,精度はというと…
* Acc@1 76.488 Acc@5 93.022
おお,確かに変換前とほぼ全く同じです.凄いですね.ただ,今回はGPUで実行したので,実行時間も変換前とあまり変わりませんでした(むしろ少し延びた?).やはり,本手法は専用チップを作った時に,その威力が発揮されるのだと思います.
まとめ
RepVGGのA2モデルの推論処理をTesla V100上で実行してみました.pip installが必要なパッケージも少ないですし,かなり簡単に試せると思います.また,学習済モデルを推論用モデルに変換しても,top-1 accuracyが全くと言っていいほど同じであることを確認しました.今後は,フルスクラッチで学習してもこの精度が出るのか,他の学習データでもうまくいくのかなどを試していきたいと思います.
当ブログでは,他にもAI分野のOSSやチュートリアルを,手を動かしながら解説していきます.
コメントを残す